Practical Inference Server Systems
Nvidia FasterTransformer library and Triton inference Server[1]
针对Transformer从两个维度进行inference的加速,
- 一个是Tensor-Parallelism,主要将不同的Tensor放到不同的Trunk中,再将trunk放到不同的Device上。
- 另一个是Pipeline-Parallelism,将model按照layer进行分割,在层上进行Pipeline。
Optimizations in FasterTransformer
- Layer Fusion:将多个layer融合到一个kernel中,加速计算。(不懂)
- Activations caching:对于QKV的cache,见下图:
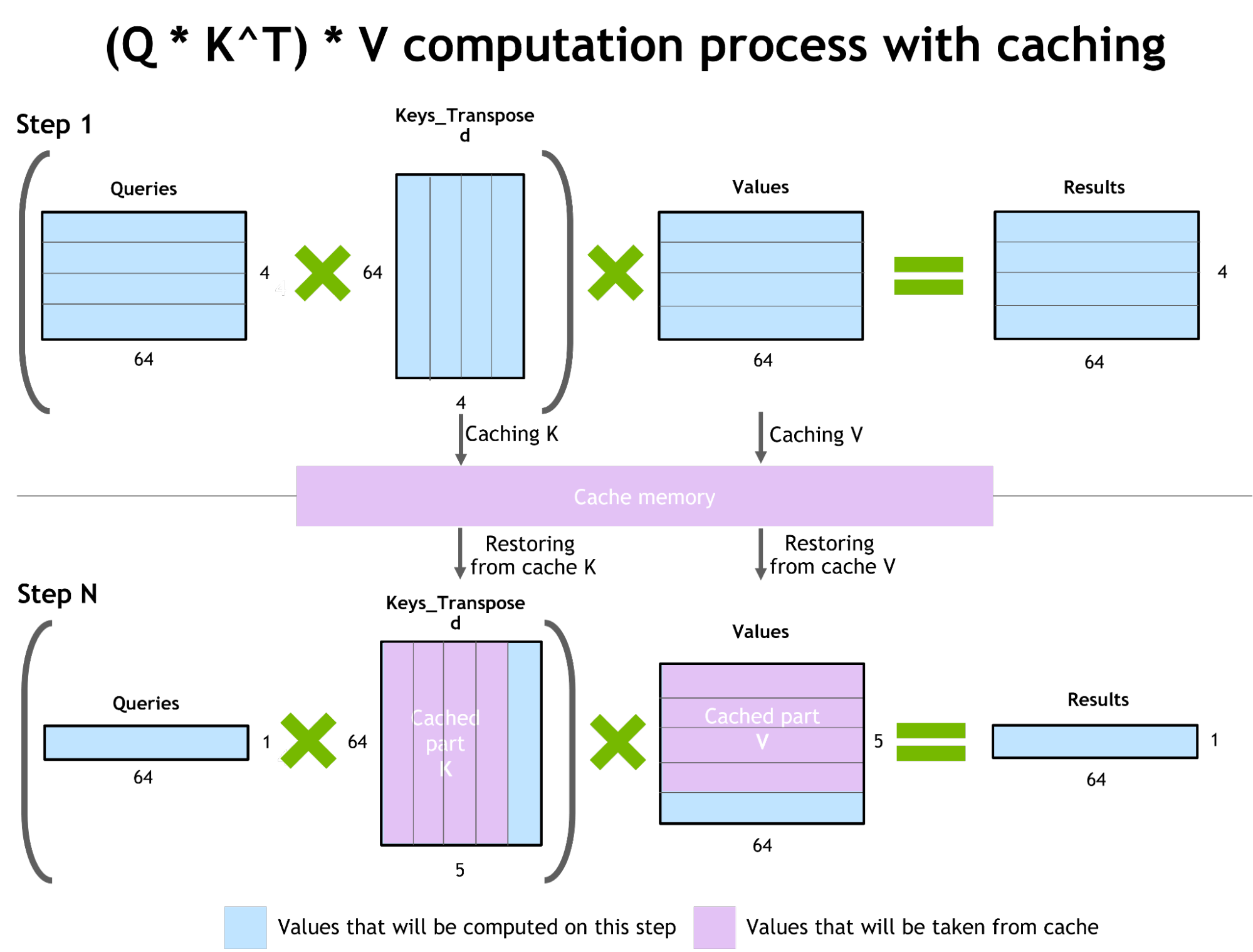
- 使用MPI和NCCL进行节点内部和节点之间的通信优化。(这里使用了类似Megatron的思路,分别对TP和PP进行优化。)
- 使用低精度运算。
Triton inference server system[2]
Tools for ML Inference Serving System
BentoML[3]
一个基于docker的ML Serving系统。支持Adaptive Batching(server-side),见下图。
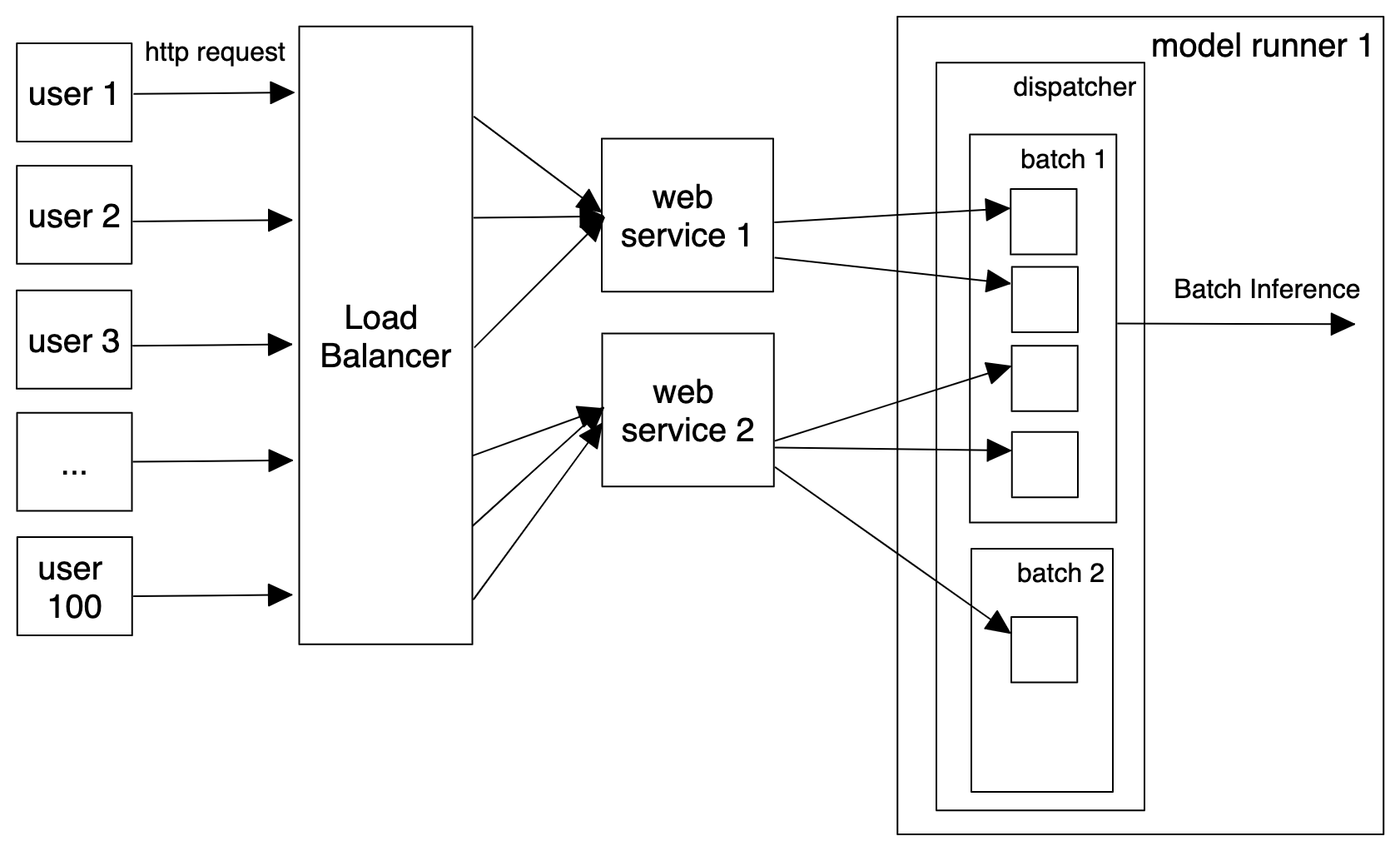
Cortex
一种可以支持多种云服务的framework。
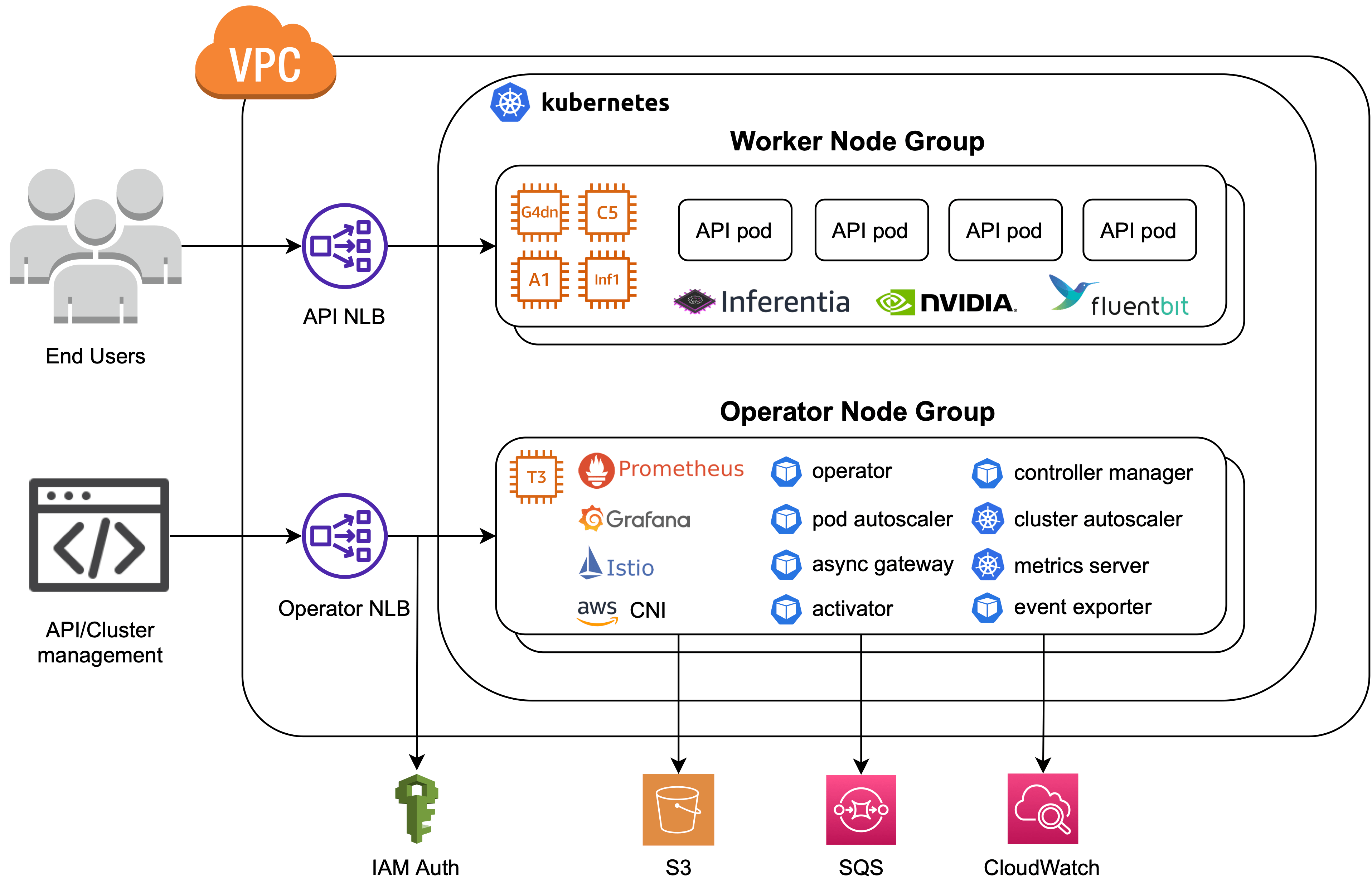
TF Serving
有点牛的。(没啥特别的,看了一下,感觉只支持TF,这没啥用啊)
TorchServe
支持非常多的metric,可以制定相关的service。
KServer
支持k8s,混合device。

Multi Model Server
支持aws。
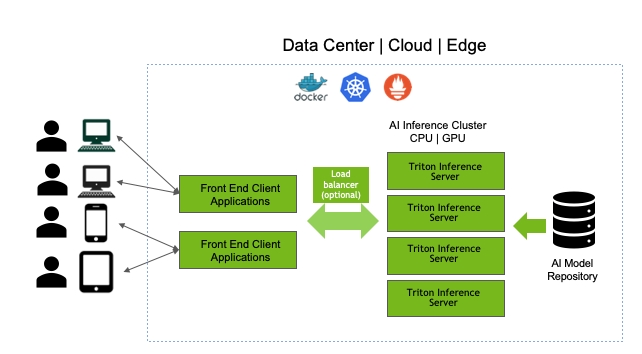
Triton Inference Server
Cloud Edge Inference Solution、支持Dynamic batching、支持model ensemble。(Nvidia的东西,有点牛的。)对于Large Model有优化。
ForestFlow
DeepDetect
Seldon Core
挺有意思的
Reference
- NVIDIA Technical Blog. 《Accelerated Inference for Large Transformer Models Using FasterTransformer and Triton Inference Server》, 2022年8月3日. https://developer.nvidia.com/blog/accelerated-inference-for-large-transformer-models-using-nvidia-fastertransformer-and-nvidia-triton-inference-server/.
- 《Triton Inference Server | NVIDIA Developer》. 见于 2022年8月18日. https://developer.nvidia.com/nvidia-triton-inference-server.
- Kijko, Pawel. 《Best Tools to Do ML Model Serving》. neptune.ai, 2021年2月15日. https://neptune.ai/blog/ml-model-serving-best-tools.